■ 3장 정리
☞ 회귀 알고리즘에 대한 학습
(일반 회귀)주변의 평균을 구해서 예측 → 결정계수(회귀모델의 점수)
→ (선형회귀) input범주를 넘어가는 범주를 예측하기
→ (다항회귀) 다항식(2차원 방정식)을 사용한 선형회귀
→ (다중회귀) 여러개의 특성을 사용한 선현회귀
☞ pandas
- 지도학습 (정답을 미리 알려주고 학습을 진행)
sklearn의 neighbors의 제공 Class
- 분류(classification) (KNeighborsClassifier, 1,2장에서 사용)
- 의미 그대로 구분지어서 분류하는것 (이전장에서 도미와, 농어를 구분)
- 회귀 (regression) (KNeighborsRegressor, 3장에서 사용)
- 예측하는것에 대한것 / 이웃에 대한 샘플에 대한 평균을 이용함
- 제공되는 데이터의 특성을 이용한다.
- 3장에서는 "k-최근접 이웃 회귀" 방법을 사용한다.
- regression test라는 단어가 익숙하다
- 전체 테스트 Set중에서 임의로 Test성공을 예측하면서, 테스트를 진행하는 방법
- 정확한 숫자를 맞히는거는 불가능 // 모두 임의의 수치이다.
- 결정계수 (R^2)
- 1차원 배열을 numpy의 reshape를 이용해서 다차원으로 변경하기
배열의 갯수와 reshape(x,y)의 x*y의 갯수는 같아야 한다.
4 = 2*2 / 1*4 / 4*1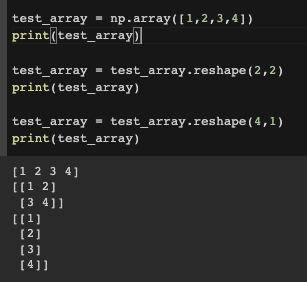
reshape(x,y)에서 x:-1, y: (np.array의 사이즈로 나누어질수있는 공약수)로 지정가능
- train_input의 사이즈가 42여서 (-1,18)은 오류가 발생한다.

- train_input의 사이즈가 42여서 (-1,18)은 오류가 발생한다.
- 분류(classification) (KNeighborsClassifier, 1,2장에서 사용)
■ 기본 미션
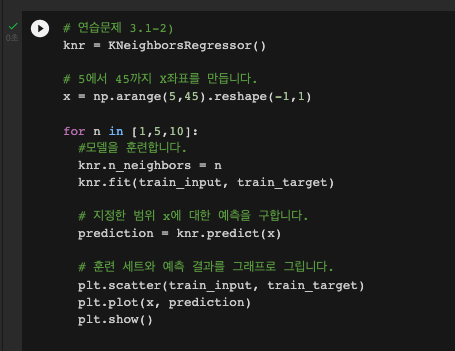
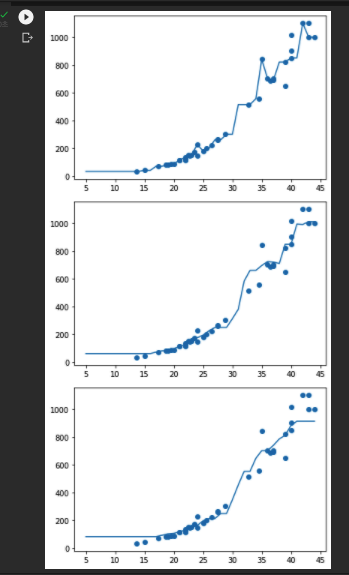
■ 선택 미션
<모델 파라미터에 대해 설명하기>
선형대수에서 기울기가 있는 선에 대해서 최적의 값을 찾기 위한 과정이며 이 값을 모델 파리미터라고 합니다.
sklearn에서는 coef_, intercept_의 값이 머신러닝을 통해서 찾은 값을 정의합니다.
선형에 기울기가 있는데 이를 계수(coefficient), 가중치(weight)라고 지정합니다.
'study' 카테고리의 다른 글
| 혼공 머신러닝/딥러닝 6주차 (0) | 2022.02.26 |
|---|---|
| 혼공 머신러닝/딥러닝 5주차 (0) | 2022.02.18 |
| 혼공 머신러닝/딥러닝 4주차 (0) | 2022.02.10 |
| 혼공 머신러닝/딥러닝 3주차 (0) | 2022.01.26 |
| 혼공 머신러닝/딥러닝 1주차 (1) | 2022.01.15 |



