요즘은 빅데이터라는 말이 잘 회자되지 않는것 같습니다.
몇해전만 해도, 가트너의 주요 키워드였습니다.
그 이유는 이제 당연한 기술이 되었다고 생각이 들었습니다.
이책의 제목이 상당히 흥미롭습니다.
"자바와 파이션으로 만드는....." 이라는 부분에 대해서 어떻게 이 책에 다 담을수 있을까 하는 호기심이 드는 책입니다.

■ 책에서 다루고 있는 빅데이터 시스템의 기술 요소들
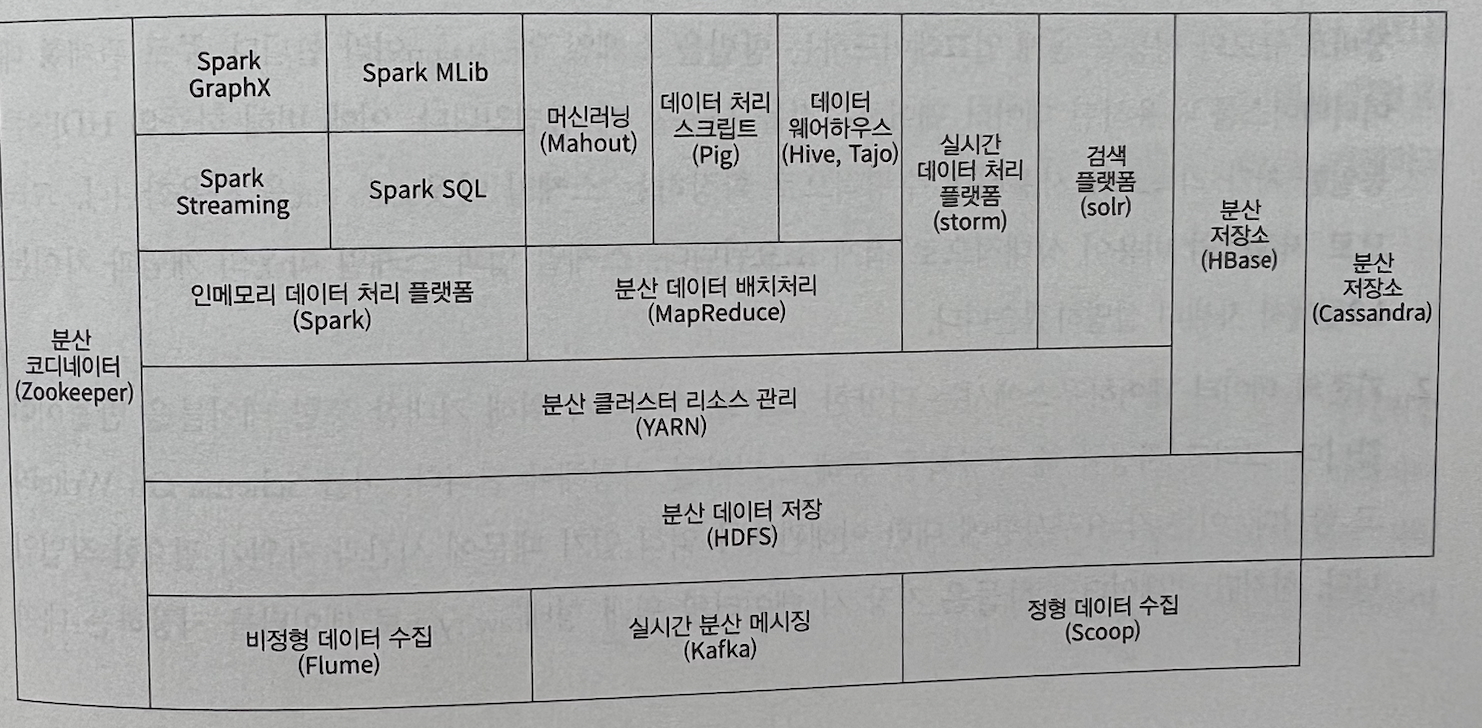
· 빅데이터를 다루는 기술은 예전에 nosql이 화두가 되면서 다양한 기술들이 소개되어지고, 언급되었습니다.
이책에서 언급되고 내용이 구성되는 기술은 "하둡", "카프카", "스파크", "MySQL", "몽고DB" 입니다.
· 책의 목차부분인데, 여러가지 빅데이터 관련 시스템에 대해서 Java, Python의 언어로 프로젝트의 예시로 구성하고 있는것을 알수 있습니다.

· 이책에서 다루는 기술적인 요소들의 실습 Flow입니다.
맨 앞에서 있는 FRED(Federal Reserve Economic Data)는 미국 세인트루이스 연방준비은행에서 관리하고 제공하는 경제통계 시계열 데이타를 의미합니다. 이 데이터를 가지고 아래의 기술요소들을 순차적으로 목적에 맞게 활용하는 실습을 해볼수 있게 책이 구성되어 있습니다. 아래의 기술요소들은 모두 각각의 책으로 구성되고, 하나하나 별로 큰 주제임은 분명합니다.
하지만, 이렇게 전체적인 관점으로 데이터를 바라보게 되면, 하나의 데이터흐름에 대해서 1-Cycle을 알수 있게 합니다.
그래서 이러한 구성은 매우 도움이 많이 됩니다.
단독으로 kafka만 사용해도 되고, Spark만 사용해도 되고, MySQL만 사용해도 되지만 우리는 조금더 큰 개념으로 flow를 파악해보고 각각의 기술의 장단점을 비교해가면서 파악할수 있는 책의 구성이라고 생각합니다

실습환경은 window11, ubuntu 22.04
java 11LTS, python 3.9.5,
IDE Eclipse(python은 Pydev를 이용해서 Eclipse을 이용함)
MySQL 11, Monggodb 6.0, Hadoop 3.3, kafka2.13, spark3.1.3
빌드 환경으로는 maven을 사용합니다.
등을 사용합니다. 대부분 안정적버전 기준으로 사용합니다.
이 책의 예시들이 java, python모두 Eclipse IDE로 통합해서 실습하는 과정이 소스 형상관리 및 개발의 편의성을 제공해주어서 정말 책의 제목처럼 "자바와 파이션으로 만드는....."의 의미를 충분히 담고 있다고 생각합니다.
동일한 환경구성하는 코드가 2개의 다른 언어를 작성된 코드를 보는 재미도 많이 있습니다.
- 데이터 : FRED, 데이터 레이크
- Hadoop HDFS : 데이터 추출(Extract), 변환하고 (Transform), 분산 클러스터에 저장 (Load)의 ETL스트림 프로세스
- kafka : 비동기적으로 Spark에 데이터 전송을 하는 분산 메시징 시스템
p.224 : 최종적으로 데이터 마트에 입력하기 위한 요소를 아래와 같이 정의합니다.
(kafka에서 토픽으로 아래와 같이 정의를 하여서 구성하는 예시입니다.)

- Spark : In-Memory처리방식, 데이터 전처리 과정에서 데이터 가공 및 적재하는 역활, 실시간 처리를 위한 스트리밍 작업
- MySQL, MongoDB : 데이터 마트 역활
- 최종적으로 데이터를 가공하고, 정제하여서 각각의 MySQL, MongoDB에 저장된 데이터를 python seabon 시각화 라이브러리를 이용해서 우리가 보고 싶은 관점의 차트를 구성해본다.


■ 빅데이터를 접해보고, 경험해볼수 있는 기회 제공
· 시스템적인 부분은 프로그램적인 부분과 비교해서 더욱더 정답이 없는 분야라고 생각됩니다. 또한 프로그램은 쉽게 혼자 또는 작은 단위로 테스트가 가능하지만, 빅데이터를 다루는 기술을 학습하고 실습하기 위해서는 기본적으로 필요한 데이터 사이즈 및 서버의 대수도 많이 필요합니다. VM을 통해서 실습하는것에 대해서는 한계가 있고, AWS 등을 통해서 실습하기에는 비용이 듭니다.
이러한 부분에 대해서 이책의 실습예제는 좋은 가이드가 됩니다.
· ETL, ELT의 개념 및 데이터 레이크, 데이터 웨어하우스, 데이터 마트에 대한 용어는 익숙하시신 분들도 계시지만, 단순히 개념적 또는 회사에서 기존에 구성되어 있는 시스템을 이용만 하고 있었지만, 실제 해당 도메인에 대한 부분의 용어 및 개념이 담당업무가 아니라서 정확한 개념은 모르시는 분들이 많을수도 있는데, 이 책을 통해서 이론적인 부분 및 각각의 차이점을 파악하기 좋습니다. 알고 보면 당연한 이야기 일수 있는 부분들의 별도의 용어 정리 및 산업계에서 통용되는 솔루션이 제공되고 사용되어 집니다.
■ hadoop관련
· 하둡의 내용이 처음에 나와서, 조금? 어? 하시는 분들도 있지 않을까 생각이 들었습니다.
2006년에 처음 hadoop의 소개되어지고, ECO System이 알려지고 그때는 인공지능은 hadoop을 통한 다양한 솔류션이 나오고, 자체적으로 구축하는 사업도 많았습니다. 지금은 많이 관심도가 식은 점은 사실입니다.
· 하지만 저는 이책에서 왜 처음에 hadoop을 소개하고 처음 기술요소의 장표로 구성하는지 책에 자세히 설명되어져서 좋았습니다.
하둡을 통해서 모든걸 다 처리하는 시점에서는 불편한 점들이 많았지만, 이제는 다양한 제품들이 그 부족한 부분을 잘 채워주고
하둡이 잘하고 효율적인 부분에 대해서 집중해서 사용하면 더 좋은 구성도가 나오게 됩니다.
- 스케일 아웃이 가능한 저비용 저장소
- 기존 데이터웨어하우스의 schema on write, schema on read
- 다양한 데이터 타입
- YARN을 통한 장애 대응
- 대규모 빅데이터를 적용하여 데이터를 모델링하고 분석 가능
■ 책의 구성 및 특징
· hadoop을 window11, ubutu에 설치하는 내용이 있는데, hadoop도 window 별도의 가상 vm을 설치하지 않고 설치할수 있는 내용을 보고 매우 흥미로웠습니다. 이러한 실습하는 과정이 다양한 OS, 특히 window기반으로 제공되는 것은 이책의 장점이라고 생각이 됩니다.
보통 설치과정에서 많은 시행착오를 가지기 때문입니다.

· 기술요소들에 대해서 기본적인 원리 및 주요 API에 대한 설명이 있어서 빠르게 동작을 해보고, 실습하는데 좋은 정보를 제공합니다.
모든 API를 다 알수는 없지만, 보통 주요한 동작을 하는 API에 대한 설명이 예시와 함께 제공되어서 이해하기가 쉽습니다.
추가로 파이션으로 hadoop에 제어하기 위해서 PyArrow패키지를 사용하고 있습니다. 보통 hadoop은 자바로 핸들링을 많이 하는데
이렇게 파이션을 통한 방법도 각자 회사의 환경에 맞게 접근할 수 있는 기회도 제공합니다.
참고로 뒤에 나올 kafka도 공식적으로는 java api를 제공하지만, python으로도 사용법이 제공되어지는 지는 구성으로 되어 있습니다.

<Eclipse에서 spark 배치작업을 하는 환경설정>

"제이펍에서 책을 제공받아 작성된 서평입니다."
'book' 카테고리의 다른 글
| 풀스택 테스트(10가지 테스트 기술의 기본 원칙과 전략) (0) | 2023.06.25 |
|---|---|
| 추천 시스템 입문 (1) | 2023.05.27 |
| 머신러닝 시스템 설계 (0) | 2023.04.22 |
| 스프링 코딩 공작소 (0) | 2023.04.09 |
| UX/UI 디자이너를 위한 실무 피그마 (0) | 2023.03.13 |



